fsteeg.com
| notes
![]() | tags
| tags
∞ /notes/metadata-processing-with-metafacture-and-eclipse | 2013-04-28 | programming eclipse metadata xtext dsl
Metadata processing with Metafacture and Eclipse
Cross-posted to: https://fsteeg.wordpress.com/2013/04/28/metadata-processing-with-metafacture-and-eclipse/
A lot has happened job-wise for me since my last post: in the summer I quit my little trip into the startup world (where I used Clojure and was not just the only Eclipse user on the team, but actually the only IDE user) and joined hbz, the Library Service Center of the German state of North Rhine-Westphalia. The library part is actually about the book thing, and it sort of divides not only the general public, but the Eclipse community as well:I’m with Alex Blewitt’s kids on this one. And for what ‘retro’ means, I recently saw a nice definition:@waynebeaton @DonaldOJDK @IanSkerrett I go with my kids to get library books every week. They think it's retro.
— Alex Blewitt (@alblue) March 5, 2013
"Gamers say we're 'retro', which I guess means 'old, but cool'" -- Wreck-It RalphOK, so libraries are old, but cool. But what’s in the library world for a programmer? Metadata!
At hbz, we don’t deal with books, but with information about books. I’m in the Linked Open Data group, where we work on bringing this library metadata to the web. At the heart of this task is processing and transforming the metadata, which is stored in different formats. In general, metadata provides information about specific aspects of some data. For libraries, the data is books, and the aspects described by the metadata are things like the book’s author, title, etc. These aspects can be represented as key-value pairs, giving metadata a structure of key-value pairs, grouped to describe the aspects of some piece of data. Given this general structure, metadata processing isn’t a problem specific to libraries. Even if you take only open, textual formats like XML or JSON, you simply have a myriad of ways to express your specific set of metadata (e.g. which keys to use, or how to represent nested structure). Given this reality of computing, metadata processing is not only at the heart of library data, but central to any data processing or information system. Therefore I was very happy to learn about a very useful toolkit for metadata processing called Metafacture, developed by our partners in the Culturegraph project at the German National Library....and if you're interested in metadata, you should be interested in library metadata. That's where metadata began.
— Bob DuCharme (@bobdc) February 22, 2013
 Metafacture is a framework for metadata processing. One basic idea of Metafacture is to separate the transformation rules from the specific input and output formats. In the transformation, key-value pairs are converted to other key-value-pairs, defined declaratively in an XML file (the Morph file). The Metafacture framework provides support for different input and output formats and is extensible for custom formats.
The interaction of input, transformation rules, and output makes up the transformation workflow. This workflow is defined in Metafacture with a domain-specific language called Flux. Since I knew about the awesome power of Xtext, I started working on tools for this DSL, in particular an Xtext-based editor and an Eclipse launcher for Flux files. I'll use these tools here to give you an idea of what Flux is about. We start the workflow by specifying the path to our input file, relative to the location of the Flux file (using a variables declared with the
Metafacture is a framework for metadata processing. One basic idea of Metafacture is to separate the transformation rules from the specific input and output formats. In the transformation, key-value pairs are converted to other key-value-pairs, defined declaratively in an XML file (the Morph file). The Metafacture framework provides support for different input and output formats and is extensible for custom formats.
The interaction of input, transformation rules, and output makes up the transformation workflow. This workflow is defined in Metafacture with a domain-specific language called Flux. Since I knew about the awesome power of Xtext, I started working on tools for this DSL, in particular an Xtext-based editor and an Eclipse launcher for Flux files. I'll use these tools here to give you an idea of what Flux is about. We start the workflow by specifying the path to our input file, relative to the location of the Flux file (using a variables declared with the default keyword). The first interesting part of the workflow is how to interpret this input path. What we mean here is the path to a local, uncompressed file:
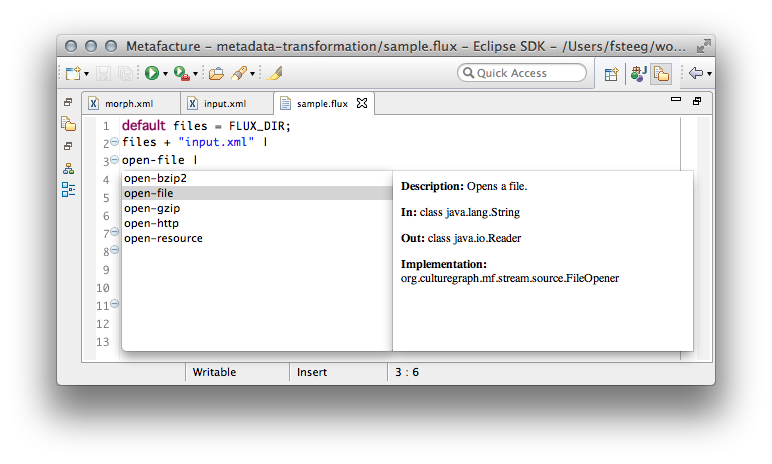 Next, we specify how to decode the information stored in the file (XML in our case):
Next, we specify how to decode the information stored in the file (XML in our case):
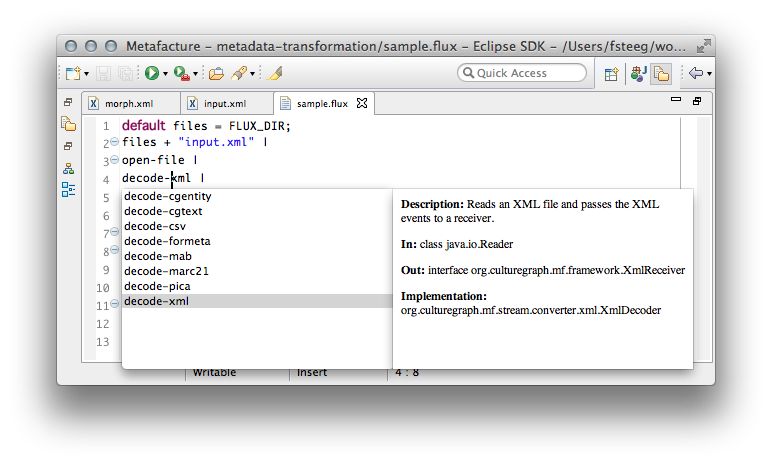 And as a separate step, how to handle this information to make it available in the grouped key-value structure used for the actual transformation (in our case, this will e.g. flatten the sub fields in the input by combining each top field key with its sub field keys):
And as a separate step, how to handle this information to make it available in the grouped key-value structure used for the actual transformation (in our case, this will e.g. flatten the sub fields in the input by combining each top field key with its sub field keys):
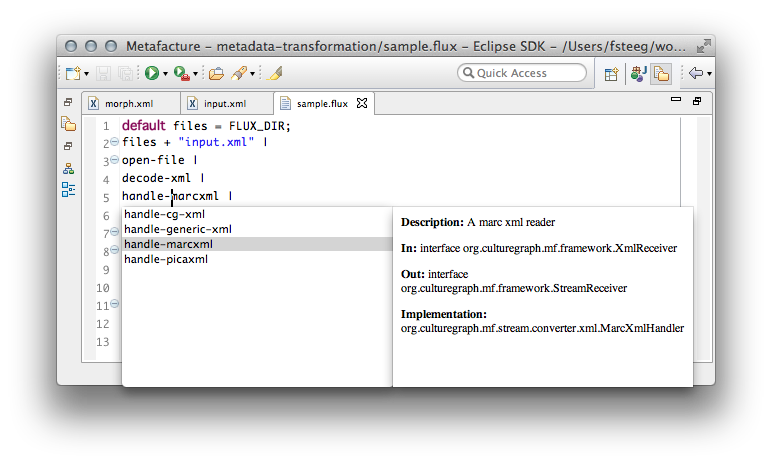 At this point we’re ready to trigger the actual transformation, which is defined in the XML Morph file. To understand the basic idea of how the transformation works, let’s open the morph.xml file with the WTP XML editor and have a look at the design tab:
At this point we’re ready to trigger the actual transformation, which is defined in the XML Morph file. To understand the basic idea of how the transformation works, let’s open the morph.xml file with the WTP XML editor and have a look at the design tab:
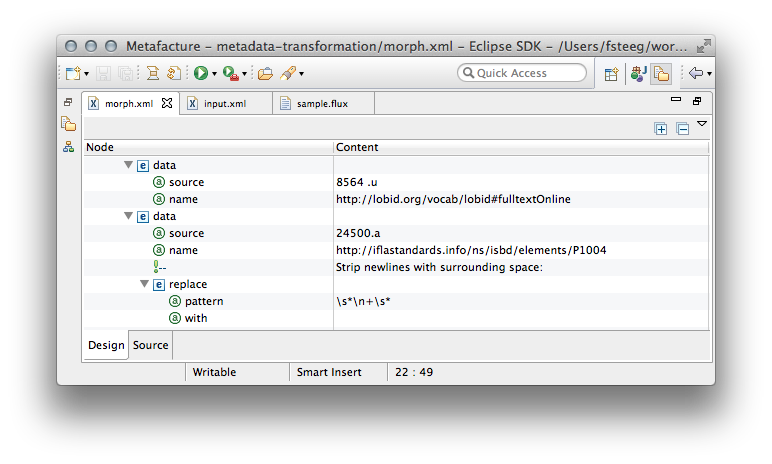 What we see here are two transformation rules for different fields of an input record. The first one just changes the attribute key: we want to map the input field
What we see here are two transformation rules for different fields of an input record. The first one just changes the attribute key: we want to map the input field 8564 .u (the URL field identifier in the MARC format) to http://lobid.org/vocab/lobid#fulltextOnline (the identifier used for full text references in our linked open data). The second rule does the same for the field 24500.a, mapping it to http://iflastandards.info/ns/isbd/elements/P1004 (the title field), but this second rule also changes the value: it removes newlines with surrounding spaces by calling the replace Morph function. There are many options in the Metafacture Morph language, but this should give you the basic idea. For details, see the Metafacture Morph user guide.
After the actual transformation, we have new key-value pairs, which we now want to encode somehow. In our use case at hbz, we want to create linked open data to be processed with Hadoop, so we wrote an encoder for N-Triples, a line-based RDF graph serialization:
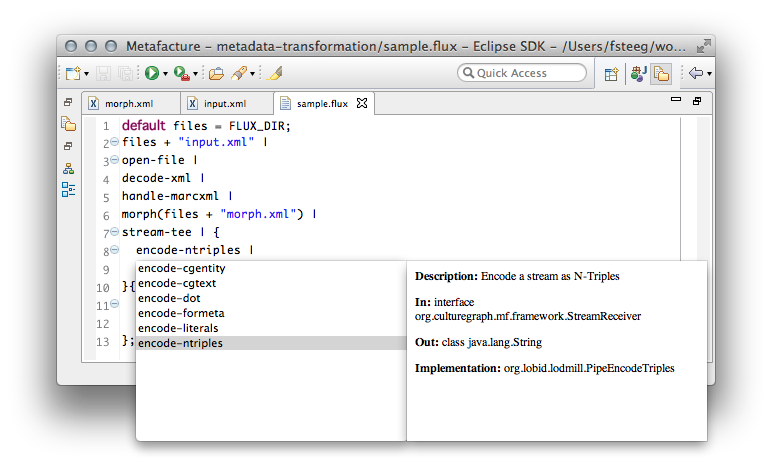 Notice how we didn’t just pipe into the
Notice how we didn’t just pipe into the encode-ntriples command, but first opened a stream-tee to branch the output of the morph command into two different receivers, one generating the mentioned N-Triples, the other creating a renderable representation of the graph in the Graphviz DOT language:
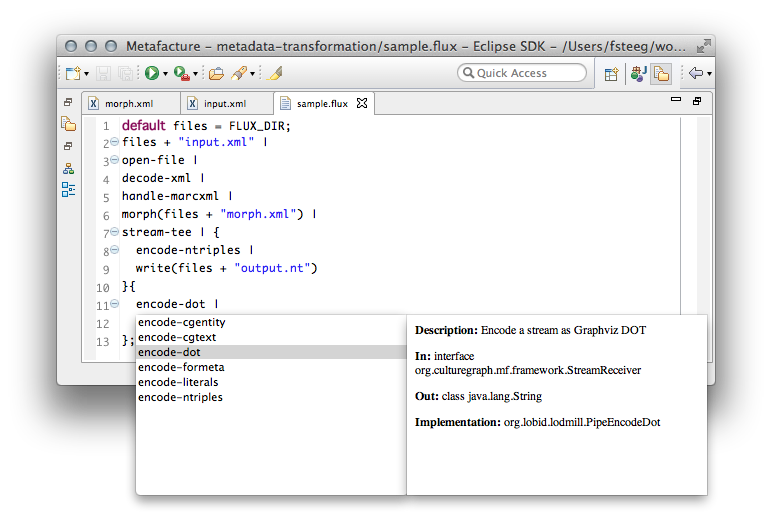 We now have a complete Flux workflow, which we can run by selecting Run -> Run As -> Flux Workflow on the Flux file (in the editor or the explorer view). This will generate the output files and refresh the workspace:
We now have a complete Flux workflow, which we can run by selecting Run -> Run As -> Flux Workflow on the Flux file (in the editor or the explorer view). This will generate the output files and refresh the workspace:
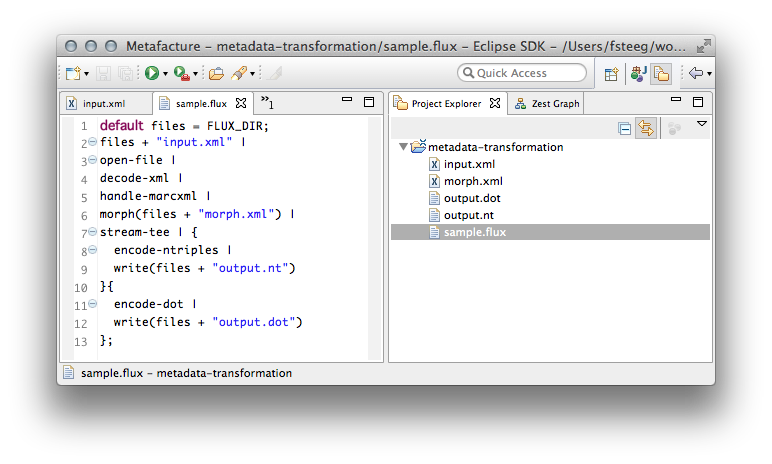 Since we’re running in Eclipse, it’s easy to integrate this with other stuff. For instance I’ve added the Zest feature to our build to make the Zest graph view available. This view can listen to DOT files in the workspace, and render their content with Zest. When enabled, the view will update as soon as the output DOT file is written by the Flux workflow, and display the resulting graph.
Check out the Metafacture IDE user guide for detailed instructions on this sample setup. The Metafacture IDE is in an early alpha stage, but we think it’s already useful. It can be installed from the Eclipse Marketplace. We’re happy about any kind of feedback, contributions, etc. There's a Metafacture IDE developer guide and further information on all Metafacture modules on GitHub.
One of the best things about Metafacture is that it is built to be extensible. Which makes sense, since you can supply tons of stuff for metadata processing, but you will never cover every format out of the box. So Metafacture helps users to solve their problems by providing hooks into the framework. For instance, both Flux commands (e.g.
Since we’re running in Eclipse, it’s easy to integrate this with other stuff. For instance I’ve added the Zest feature to our build to make the Zest graph view available. This view can listen to DOT files in the workspace, and render their content with Zest. When enabled, the view will update as soon as the output DOT file is written by the Flux workflow, and display the resulting graph.
Check out the Metafacture IDE user guide for detailed instructions on this sample setup. The Metafacture IDE is in an early alpha stage, but we think it’s already useful. It can be installed from the Eclipse Marketplace. We’re happy about any kind of feedback, contributions, etc. There's a Metafacture IDE developer guide and further information on all Metafacture modules on GitHub.
One of the best things about Metafacture is that it is built to be extensible. Which makes sense, since you can supply tons of stuff for metadata processing, but you will never cover every format out of the box. So Metafacture helps users to solve their problems by providing hooks into the framework. For instance, both Flux commands (e.g. open-file, decode-xml in the Flux file above) and Morph functions (e.g. replace in the Morph XML file above) are actually Java classes implementing specific interfaces that are called using reflection internally. The additional content assist information above is generated from annotations on these classes.
With its stream-based processing pipeline inspired by an architecture developed by Jörg Prante at hbz, Metafacture is efficient and can deal with big data. With its declarative, modular setup with Morph and Flux files Metafacture provides accurate, complete, and reproducible documentation on how the data was created.
 I think the nature of this work as well as the organizational challenges in the library community, where multiple public and commercial entities both cooperate and compete, make Eclipse a great model - both technically (build for extensibility, use a common platform, etc) and for open source governance (transparency, vendor neutrality, etc). I’m therefore very happy that hbz recently joined the Eclipse Foundation as an associate member.
I think the nature of this work as well as the organizational challenges in the library community, where multiple public and commercial entities both cooperate and compete, make Eclipse a great model - both technically (build for extensibility, use a common platform, etc) and for open source governance (transparency, vendor neutrality, etc). I’m therefore very happy that hbz recently joined the Eclipse Foundation as an associate member.